
-
多对多建表原则1
-
多对多建表原则2
可以在 SELECT, UPDATE 和 DELETE 语句中使用 Mysql 的 JOIN 来联合多表查询。
JOIN 按照功能大致分为如下三类:
- INNER JOIN(内连接,或等值连接):获取两个表中字段匹配关系的记录。
- LEFT JOIN(左连接):获取左表所有记录,即使右表没有对应匹配的记录。
- RIGHT JOIN(右连接): 与 LEFT JOIN 相反,用于获取右表所有记录,即使左表没有对应匹配的记录。
- 交叉连接查询 笛卡尔积SELECT * FROM product;SELECT * FROM category;笛卡尔积 ,查出来是两张表的乘积 ,查出来的结果没有意义SELECT * FROM product,category;--过滤出有意义的数据SELECT * FROM product,category WHERE cno=cid;SELECT * FROM product AS p,category AS c WHERE p.cno=c.cid;SELECT * FROM product p,category c WHERE p.cno=c.cid;--数据准备INSERT INTO product VALUES(NULL,'耐克帝',10,NULL);- 内连接查询-- 隐式内链接 SELECT * FROM product p,category c WHERE p.cno=c.cid;-- 显示内链接 SELECT * FROM product p INNER JOIN category c ON p.cno=c.cid; -- 区别: 隐式内链接: 在查询出结果的基础上去做的WHERE条件过滤 显示内链接: 带着条件去查询结果, 执行效率要高- 左外连接 左外连接,会将左表中的所有数据都查询出来, 如果右表中没有对应的数据,用NULL代替 SELECT * FROM product p LEFT OUTER JOIN category c ON p.cno=c.cid;- 准备工作 INSERT INTO category VALUES(100,'电脑办公','电脑叉叉差');- 右外连接: 会将右表所有数据都查询出来, 如果左表没有对应数据的话, 用NULL代替 SELECT * FROM product p RIGHT OUTER JOIN category c ON p.cno=c.cid; -- 查询分类名称为手机数码的所有商品 1.查询分类名为手机数码的ID SELECT cid FROM category WHERE cname='手机数码'; 2.得出ID为1的结果 SELECT * FROM product WHERE cno = (SELECT cid FROM category WHERE cname='手机数码'); -- 查询出(商品名称,商品分类名称)信息 --左连接 SELECT p.pname,c.cname FROM product p LEFT OUTER JOIN category c ON p.cno = c.cid; --子查询 SELECT pname ,(SELECT cname FROM category c WHERE p.cno=c.cid ) AS 商品分类名称 FROM product p; CREATE TABLE emp( empno INT, ename VARCHAR(50), job VARCHAR(50), mgr INT, hiredate DATE, sal DECIMAL(7,2), comm DECIMAL(7,2), deptno INT) ;INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);INSERT INTO emp VALUES(7981,'MILLER','CLERK',7788,'1992-01-23',2600,500,20);CREATE TABLE dept( deptno INT, dname VARCHAR(14), loc VARCHAR(13));INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK');INSERT INTO dept VALUES(20, 'RESEARCH', 'DALLAS');INSERT INTO dept VALUES(30, 'SALES', 'CHICAGO');INSERT INTO dept VALUES(40, 'OPERATIONS', 'BOSTON');--最高工资SELECT MAX(sal) FROM emp;--最少工资SELECT MIN(sal) FROM emp;--最高工资的员工信息SELECT * FROM emp WHERE sal = (SELECT MAX(sal) FROM emp);--最低工资的员工信息SELECT * FROM emp WHERE sal = (SELECT MIN(sal) FROM emp);-- 单行子查询(> < >= <= = <>) -- 查询出高于10号部门的平均工资的员工信息 1.10号部门的平均工资 SELECT AVG(sal) FROM emp WHERE deptno = 10; 2. 高于上面结果员工信息 SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno = 10); -- 多行子查询(in not in any all) >any >all -- 查询出比10号部门任何员工薪资高的员工信息 1. 查询出10号部门最高工资 SELECT MAX(sal) FROM emp WHERE deptno = 10; 2. 得出结果 SELECT * FROM emp WHERE sal > (SELECT MAX(sal) FROM emp WHERE deptno = 10); -- 查询出比10号部门任意一个员工薪资高的所有员工信息 : 只要比其中随便一个工资都可以 SELECT sal FROM emp WHERE deptno = 10; SELECT * FROM emp WHERE sal >ANY(SELECT sal FROM emp WHERE deptno = 10) AND deptno != 10; -- 多列子查询(实际使用较少) in -- 和10号部门同名同工作的员工信息 1. 查询出10号部门所有人 名字和工作 SELECT ename,job FROM emp WHERE deptno=10; 2. 得出结果 SELECT * FROM emp WHERE (ename,job) IN (SELECT ename,job FROM emp WHERE deptno=10) AND deptno !=10;-- Select后面接子查询 -- 获取员工的名字和部门的名字 SELECT ename,deptno FROM emp ; SELECT ename,(SELECT dname FROM dept d WHERE d.deptno = e.deptno ) 部门名称 FROM emp e ;-- from后面接子查询 -- 查询emp表中所有管理层的信息 SELECT DISTINCT mgr FROM emp; - 得出结果 SELECT * FROM emp e,(SELECT DISTINCT mgr FROM emp) mgrtable WHERE e.empno = mgrtable.mgr; -- where 接子查询 -- 薪资高于10号部门平均工资的所有员工信息 1. 10号部门平均工资 SELECT AVG(sal) FROM emp WHERE deptno=10; 2. 得出结果 SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno=10); -- having后面接子查询 -- 有哪些部门的平均工资高于30号部门的平均工资 1. 统计所有的部门的平均工资 SELECT deptno, AVG(sal) FROM emp GROUP BY deptno; 2. 30号部门的平均工资 SELECT AVG(sal) FROM emp WHERE deptno=30; 3.得出结果: SELECT deptno, AVG(sal) FROM emp GROUP BY deptno HAVING AVG(sal) > (SELECT AVG(sal) FROM emp WHERE deptno=30);-- 列出达拉斯加工作的人中,比纽约平均工资高的人 1. 查处达拉斯加工作的人 1. 查询出达拉斯的部门编号 SELECT deptno FROM dept WHERE loc ='DALLAS'; 2. SELECT * FROM emp WHERE deptno = ( SELECT deptno FROM dept WHERE loc ='DALLAS'); 2. 查出纽约工作的人的平均工资 1. 查处纽约的部门编号 SELECT deptno FROM dept WHERE loc ='NEW YORK'; 2. SELECT AVG(sal) FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc ='NEW YORK'); 3. 得出最终结果: SELECT * FROM emp WHERE deptno = ( SELECT deptno FROM dept WHERE loc ='DALLAS') AND sal > (SELECT AVG(sal) FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc ='NEW YORK'));
CREATE TABLE emp( empno INT, ename VARCHAR(50), job VARCHAR(50), mgr INT, hiredate DATE, sal DECIMAL(7,2), comm DECIMAL(7,2), deptno INT) ;INSERT INTO emp VALUES(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20);INSERT INTO emp VALUES(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30);INSERT INTO emp VALUES(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30);INSERT INTO emp VALUES(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20);INSERT INTO emp VALUES(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30);INSERT INTO emp VALUES(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30);INSERT INTO emp VALUES(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10);INSERT INTO emp VALUES(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20);INSERT INTO emp VALUES(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10);INSERT INTO emp VALUES(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30);INSERT INTO emp VALUES(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20);INSERT INTO emp VALUES(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30);INSERT INTO emp VALUES(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20);INSERT INTO emp VALUES(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10);INSERT INTO emp VALUES(7981,'MILLER','CLERK',7788,'1992-01-23',2600,500,20);CREATE TABLE dept( deptno INT, dname VARCHAR(14), loc VARCHAR(13));INSERT INTO dept VALUES(10, 'ACCOUNTING', 'NEW YORK');INSERT INTO dept VALUES(20, 'RESEARCH', 'DALLAS');INSERT INTO dept VALUES(30, 'SALES', 'CHICAGO');INSERT INTO dept VALUES(40, 'OPERATIONS', 'BOSTON');DESC SELECT dname FROM dept WHERE deptno=10;-- 单行子查询(> < >= <= = <>) -- 查询出高于10号部门的平均工资的员工信息 1.查询出10号部门的平均工资 SELECT AVG(sal) FROM emp WHERE deptno = 10; 2.查询出高于10号部门平均工资的员工信息 SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno = 10);-- 多行子查询(in not in any all) >any >all -- 查询出比10号部门任何员工薪资高的员工信息 1. 查询出10号部门的所有工资信息 SELECT sal FROM emp WHERE deptno=10; 2.得出结果 SELECT * FROM emp WHERE sal >ALL(SELECT sal FROM emp WHERE deptno=10); -- 多列子查询(实际使用较少) in -- 和10号部门同名同工作的员工信息 1.查出10号部门员工名字和工作信息 SELECT ename,job FROM emp WHERE deptno=10; 2. 得出结果: SELECT * FROM emp WHERE (ename,job) IN (SELECT ename,job FROM emp WHERE deptno=10) AND deptno!=10;-- Select接子查询 -- 获取员工的名字和部门的名字 1.查出员工的名字和部门编号信息 SELECT ename,deptno FROM emp; 2.得出结果 SELECT ename,(SELECT dname FROM dept WHERE dept.deptno=emp.deptno) FROM emp;-- from后面接子查询 -- 查询emp表中经理信息 1.查询出所有经理的ID SELECT DISTINCT mgr FROM emp; 2. 查出经理的信息,只要id在第一步的查询结果中就可以了 SELECT * FROM emp,(SELECT DISTINCT mgr FROM emp) mgrs WHERE emp.empno = mgrs.mgr;-- where 接子查询 -- 薪资高于10号部门平均工资的所有员工信息 1.查询出10号部门的平均工资 SELECT AVG(sal) FROM emp WHERE deptno=10; 2.得出结果: SELECT * FROM emp WHERE sal > (SELECT AVG(sal) FROM emp WHERE deptno=10);-- having后面接子查询 -- 有哪些部门的平均工资高于30号部门的平均工资 1.30号部门的平均工资 SELECT AVG(sal) FROM emp WHERE deptno=30; 2. 统计所有部门的平均工资 SELECT deptno,AVG(sal) FROM emp GROUP BY deptno ; 3. 得出最终的结果 SELECT deptno,AVG(sal) FROM emp GROUP BY deptno HAVING AVG(sal) > (SELECT AVG(sal) FROM emp WHERE deptno=30); -- 工资>JONES工资的员工信息 1.查处JONES的工资信息 SELECT sal FROM emp WHERE ename='JONES'; 2.得出结果 SELECT * FROM emp WHERE sal > (SELECT sal FROM emp WHERE ename='JONES');-- 查询与SCOTT同一个部门的员工 1.查处SCOTT的部门编号 SELECT deptno FROM emp WHERE ename = 'SCOTT'; 2.得出结果 SELECT * FROM emp WHERE deptno = (SELECT deptno FROM emp WHERE ename = 'SCOTT');-- 工资高于30号部门所有人的员工信息 1.得出30号部门的最大工资 SELECT MAX(sal) FROM emp WHERE deptno = 30; 2.得出结果 SELECT * FROM emp WHERE sal > (SELECT MAX(sal) FROM emp WHERE deptno = 30);-- 查询工作和工资与MARTIN完全相同的员工信息 1.查处MARTIN的工作和工资 SELECT job,sal FROM emp WHERE ename='MARTIN'; 2.得出结果 SELECT * FROM emp WHERE (job,sal) IN (SELECT job,sal FROM emp WHERE ename='MARTIN');-- 有两个以上直接下属的员工信息 1.查出emp表中mgr信息 SELECT mgr FROM emp; 2.分组统计mgr的信息 SELECT mgr,COUNT(*) FROM emp GROUP BY mgr HAVING COUNT(*)>2; 3.得出结果 SELECT * FROM emp e1 WHERE e1.empno IN (SELECT e2.mgr FROM emp e2 GROUP BY e2.mgr HAVING COUNT(*)>2);-- 查询员工编号为7788的员工名称,员工工资,部门名称,部门地址 1.将员工表和部门表链接起来 SELECT * FROM emp ,dept WHERE emp.deptno = dept.deptno; 2.得出ID为7788的所有信息 SELECT * FROM emp ,dept WHERE emp.deptno = dept.deptno AND empno=7788; 3.只显示其中的需要的信息 SELECT ename,sal ,dname, loc FROM emp ,dept WHERE emp.deptno = dept.deptno AND empno=7788;-- 1. 查询出高于本部门平均工资的员工信息 1. 分组统计每个部门的平均工资 SELECT deptno,AVG(sal) FROM emp GROUP BY deptno; 2. 得出相应的结果 SELECT * FROM emp e1 WHERE e1.sal > (SELECT AVG(e2.sal) FROM emp e2 WHERE e1.deptno=e2.deptno GROUP BY e2.deptno); -- 1. 列出达拉斯加工作的人中,比纽约平均工资高的人 0. 查处DALLAS 的部门编号 SELECT deptno FROM dept WHERE loc='DALLAS'; 1.查处达拉斯工作的人的信息 SELECT * FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc='DALLAS'); 2. 查处纽约的部门编号 SELECT deptno FROM dept WHERE loc='NEW YORK'; 3. 查村纽约平均工资 SELECT AVG(sal) FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc='NEW YORK'); 4.得出结果: SELECT * FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc='DALLAS') AND sal > (SELECT AVG(sal) FROM emp WHERE deptno = (SELECT deptno FROM dept WHERE loc='NEW YORK')); -- 2. 查询7369员工编号,姓名,经理编号和经理姓名 SELECT e1.empno,e1.ename,e1.mgr,mgrtable.ename FROM emp e1,emp mgrtable WHERE e1.mgr = mgrtable.empno; -- 3. 查询出各个部门薪水最高的员工所有信息 1.分组统计每个部门员工最高的薪资是多少 SELECT MAX(sal),deptno FROM emp GROUP BY deptno; 2.算出结果 SELECT * FROM emp e1 WHERE e1.sal = (SELECT MAX(sal) FROM emp e2 WHERE e1.deptno = e2.deptno GROUP BY deptno); CREATE TABLE test( NAME CHAR(20), kecheng CHAR(20), fenshu CHAR(20));INSERT INTO test VALUES('张三','语文',81),('张三','数学',75),('李四','语文',76),('李四','数学',90),('王五','语文',81),('王五','数学',82);SELECT NAME FROM test WHERE fenshu < 80 ;SELECT NAME FROM test WHERE NAME NOT IN(SELECT NAME FROM test WHERE fenshu < 80 ); 回顾:
数据库的创建 : create database 数据库的名 character set 字符集 collate 校对规则
数据库的删除: drop database 数据库名
修改: alter database 数据库 character set 字符集(utf8)
查询: show databases;
show create database 数据库的名字
select database();
切换数据库 :
use 数据库的名字
表结构的操作:
创建: create table 表名(
列名 列的类型 列的约束,
列名 列的类型 列的约
)
列的类型: char / varchar
列的约束:
primary key 主键约束
unique : 唯一约束
not null 非空约束
自动增长 : auto_increment
删除 : drop table 表名
修改: alter table 表名 (add, modify, change , drop)
rename table 旧表名 to 新表名
alter table 表名 character set 字符集
查询表结构:
show tables; 查询出所有的表
show create table 表名: 表的创建语句, 表的定义
desc 表名: 表的结构
表中数据的操作
插入: insert into 表名(列名,列名) values(值1,值2);
删除: delete from 表名 [where 条件]
修改: update 表名 set 列名='值' ,列名='值' [where 条件];
查询: select [distinct] * [列名1,列名2] from 表名 [where 条件]
as关键字: 别名
where条件后面:
关系运算符: > >= < <= != <>
--判断某一列是否为空: is null is not null
in 在某范围内
between...and
逻辑运算符: and or not
模糊查询: like
_ : 代表单个字符
%: 代表的是多个字符
分组: group by
分组之后条件过滤: having
聚合函数: sum() ,avg() , count() ,max(), min()
排序: order by (asc 升序, desc 降序)
SQL 会创建多表及多表的关系
需求:
分类表和商品表之间是不是有关系? 如果有关系,在数据库中如何表示这种关系
sql create table category( cid int primary key auto_increment, cname varchar(10), cdesc varchar(31) );insert into category values(null,'手机数码','电子产品,黑马生产'); insert into category values(null,'鞋靴箱包','江南皮鞋厂倾情打造'); insert into category values(null,'香烟酒水','黄鹤楼,茅台,二锅头'); insert into category values(null,'酸奶饼干','娃哈哈,蒙牛酸酸乳'); insert into category values(null,'馋嘴零食','瓜子花生,八宝粥,辣条');select * from category; select cname,cdesc from category;--所有商品 1.商品ID 2.商品名称 3.商品的价格 4.生产日期 5.商品分类ID商品和商品分类 : 所属关系 create table product( pid int primary key auto_increment, pname varchar(10), price double, pdate timestamp, cno int );insert into product values(null,'小米mix4',998,null,1); insert into product values(null,'锤子',2888,null,1); insert into product values(null,'阿迪王',99,null,2); insert into product values(null,'老村长',88,null,3); insert into product values(null,'劲酒',35,null,3); insert into product values(null,'小熊饼干',1,null,4); insert into product values(null,'卫龙辣条',1,null,5); insert into product values(null,'旺旺大饼',1,null,5);//插入数据会失败 insert into product values(null,'充气的',1,null,12);
技术分析:
-
多表之间的关系如何来维护
外键约束: foreign key
-
给product中的这个cno 添加一个外键约束
alter table product add foreign key(cno) references category(cid);
-
自己挖坑
-
从分类表中,删除分类为5信息,
- delete from category where cid =5; //删除失败
- 首先得去product表, 删除所有分类ID5 商品
-
建数据库原则:
-
通常情况下,一个项目/应用建一个数据库
-
-
多表之间的建表原则
-
一对多 : 商品和分类
- 建表原则: 在多的一方添加一个外键,指向一的一方的主键
-
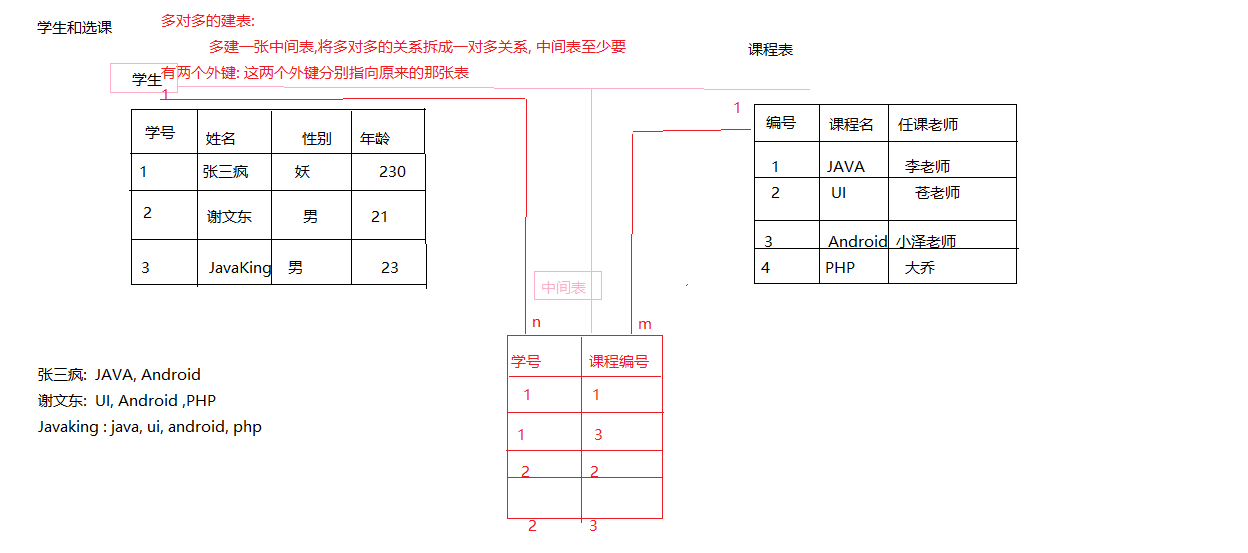
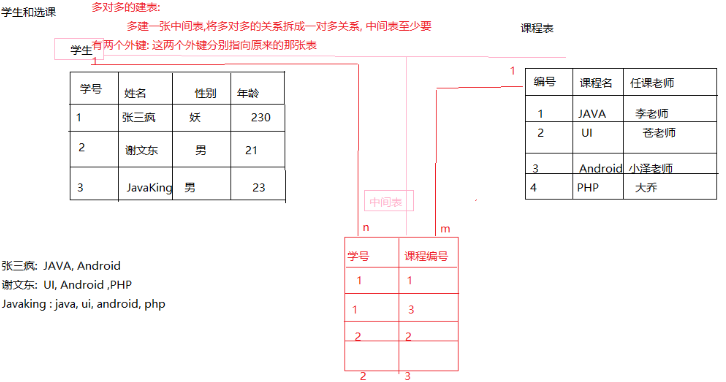
多对多: 老师和学生, 学生和课程
建表原则: 建立一张中间表,将多对多的关系,拆分成一对多的关系,中间表至少要有两个外键,分别指向原来的那两张表
-
-
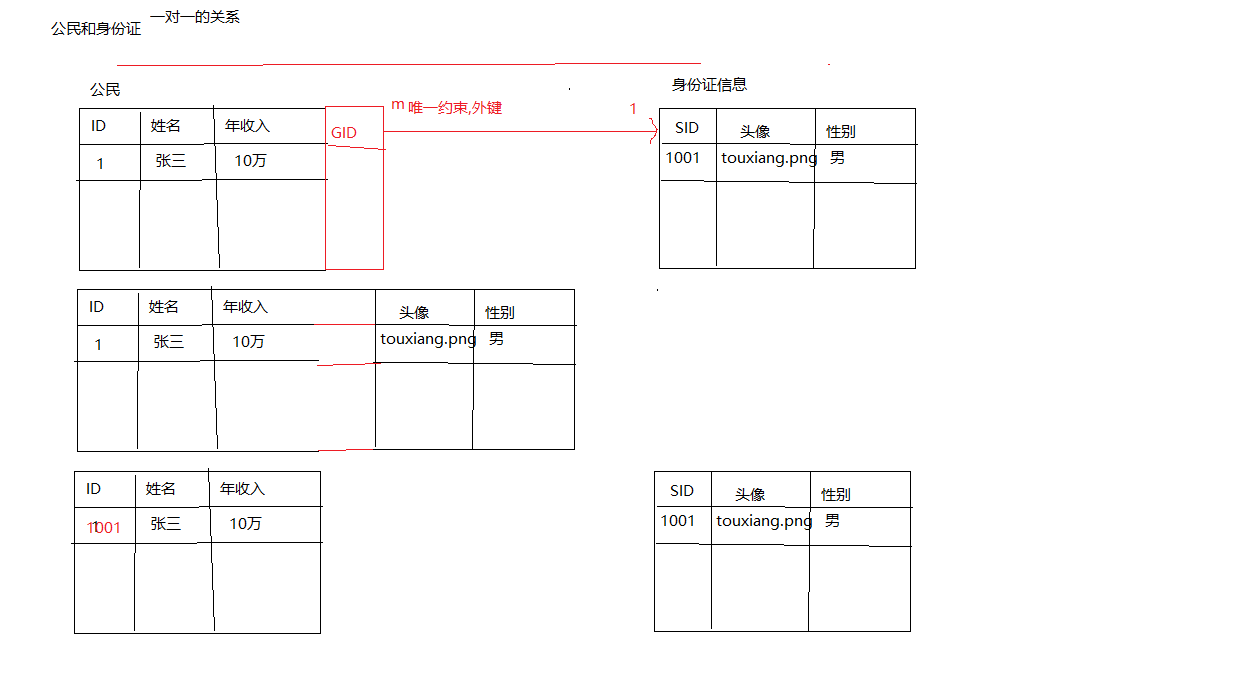
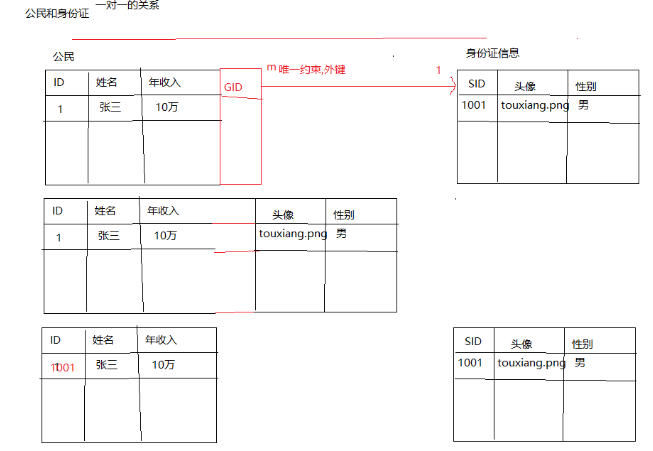
一对一: 班级和班长, 公民和身份证, 国家和国旗
-
建表原则:
- 将一对一的情况,当作是一对多情况处理,在任意一张表添加一个外键,并且这个外键要唯一,指向另外一张表
- 直接将两张表合并成一张表
- 将两张表的主键建立起连接,让两张表里面主键相等
-
-
实际用途: 用的不是很多. (拆表操作 )
- 相亲网站:
- 个人信息 : 姓名,性别,年龄,身高,体重,三围,兴趣爱好,(年收入, 特长,学历, 职业, 择偶目标,要求)
- 拆表操作 : 将个人的常用信息和不常用信息,减少表的臃肿,
-
-
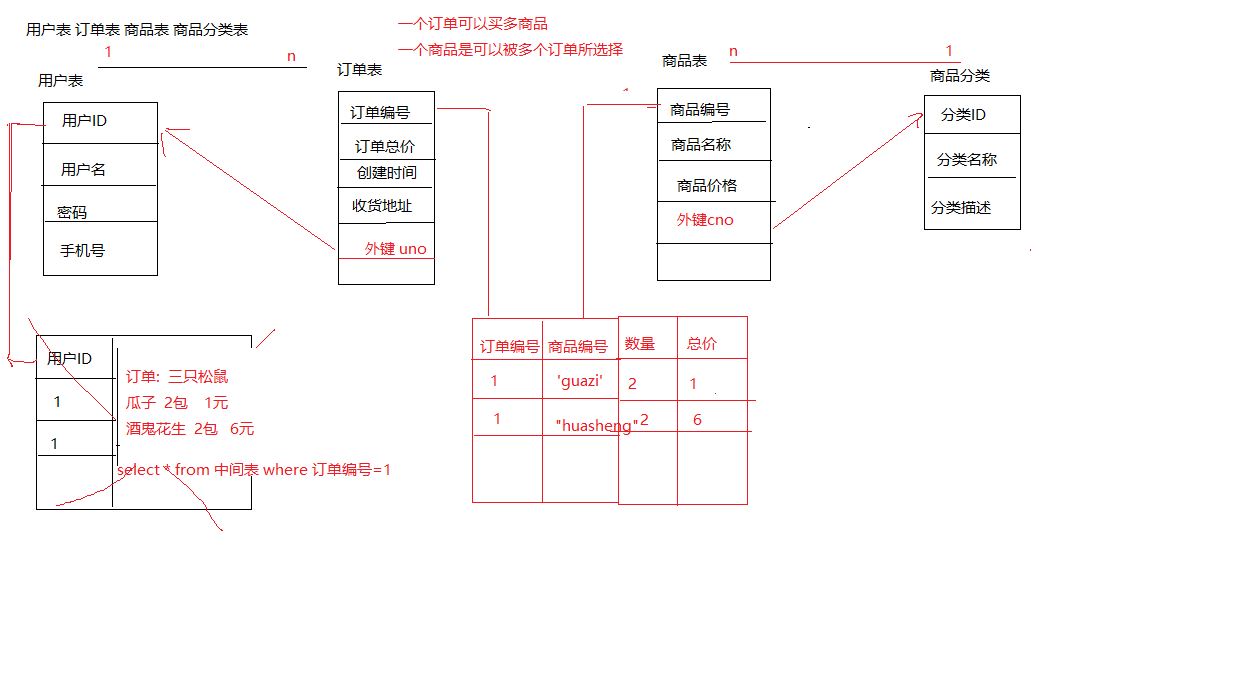
- 网上商城表实例的分析: 用户购物流程
- 用户表 (用户的ID,用户名,密码,手机)
sql create table user( uid int primary key auto_increment, username varchar(31), password varchar(31), phone varchar(11) );insert into user values(1,'zhangsan','123','13811118888');
- 订单表 (订单编号,总价,订单时间 ,地址,外键用户的ID)
sql create table orders( oid int primary key auto_increment, sum int not null, otime timestamp, address varchar(100), uno int, foreign key(uno) references user(uid) ); insert into orders values(1,200,null,'黑马前台旁边小黑屋',1); insert into orders values(2,250,null,'黑马后台旁边1702',1);
-
商品表 (商品ID, 商品名称,商品价格,外键cno)
sql create table product( pid int primary key auto_increment, pname varchar(10), price double, cno int, foreign key(cno) references category(cid) );insert into product values(null,'小米mix4',998,1); insert into product values(null,'锤子',2888,1); insert into product values(null,'阿迪王',99,2); insert into product values(null,'老村长',88,3); insert into product values(null,'劲酒',35,3); insert into product values(null,'小熊饼干',1,4); insert into product values(null,'卫龙辣条',1,5); insert into product values(null,'旺旺大饼',1,5);
-
订单项: 中间表(订单ID,商品ID,商品数量,订单项总价)
sql create table orderitem( ono int, pno int, foreign key(ono) references orders(oid), foreign key(pno) references product(pid), ocount int, subsum double ); --给1号订单添加商品 200块钱的商品 insert into orderitem values(1,7,100,100); insert into orderitem values(1,8,101,100);--给2号订单添加商品 250块钱的商品 () insert into orderitem values(2,5,1,35); insert into orderitem values(2,3,3,99);
-
商品分类表(分类ID,分类名称,分类描述)
sql create table category( cid int primary key auto_increment, cname varchar(15), cdesc varchar(100) );insert into category values(null,'手机数码','电子产品,黑马生产'); insert into category values(null,'鞋靴箱包','江南皮鞋厂倾情打造'); insert into category values(null,'香烟酒水','黄鹤楼,茅台,二锅头'); insert into category values(null,'酸奶饼干','娃哈哈,蒙牛酸酸乳'); insert into category values(null,'馋嘴零食','瓜子花生,八宝粥,辣条');
-
主键约束: 默认就是不能为空, 唯一
- 外键都是指向另外一张表的主键
- 主键一张表只能有一个
唯一约束: 列面的内容, 必须是唯一, 不能出现重复情况, 为空
- 唯一约束不可以作为其它表的外键
- 可以有多个唯一约束
一对多 : 建表原则: 在多的一方添加一个外键,指向一的一方
多对多: 建表原则:
拆成一对多
创建一张中间表, 至少要有两个外键, 指向原来的表
一对一: 建表原则: 合并一张表, 将主键建立关系 , 将它当作一对多的情况来处理
- 数据库客户端软件
使用商城表完成对商品信息的多表查询
需求分析:
在我们的商城案例中,我的订单中包含很多信息.打开我的订单需要去查询表
技术分析:
多表查询
-
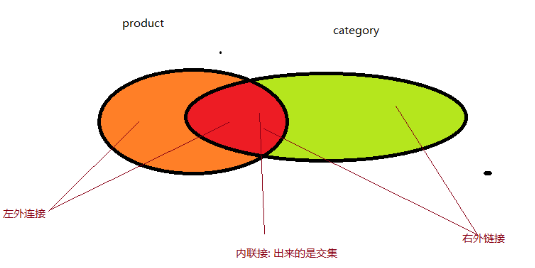
交叉连接查询 笛卡尔积
-
select * from product
-
select * from category
-
笛卡尔积,查询出来的是两张表的乘积,结果没有意义
-
select * from product,category ;
-
过滤出有意义的数据
-
select * from product,category where cno=cid;
-
取个别名可以更好地指导cno和cid出自哪里
-
select * from product AS p,category AS c WHERE p.cno=c.cid;
-
AS关键字还可以省略掉
-
select * from product p,category c WHERE p.cno=c.cid;
-
-
-
-
内连接查询
-
隐式内连接
-
select * from product p,category c WHERE p.cno=c.cid;
-
-
显示内连接
-
select * from product p INNER JOIN category c ON p.cno=c.cid;
-
-
区别
-
隐式内连接:在查询出结果的基础上去做WHERE条件过滤
-
显示内连接:带着条件查询结果,执行效率更高
-
-
-
左外连接
-
select * from product p LEFT OUTER JOIN category c ON p.cno=c.cid;
-
将左表中的数据(product)全部查询出来,如果是右表中(category)中没有对应的数据,用NULL表示
-
-
右外连接
-
将右表中的数据(product)全部查询出来,如果是左表中(category)中没有对应的数据,用NULL表示
-
select * from product p RIGHT OUTER JOIN category c ON p.cno=c.cid;
-
分页查询
-
每页数据数据3
-
起始索引从0
-
第1页: 0
-
第2页: 3
起始索引: index 代表显示第几页 页数从1开始
每页显示3条数据
startIndex = (index-1)*3
第一个参数是索引
第二个参数显示的个数
select * from product limit 0,3; 0:起始索引 3:每页几条数据
select * from product limit 3,3;
子查询(了解的内容,非常重要)
查询出(商品名称,商品分类名称)信息
--左连接
selct p.pname,c.cname from product p LEFT OUTER category c ON p.cno=c.cid
--子查询
slelect pname,(select cname from category c where p.cno=c.cid) AS 商品分类 FROM product p;
查询分类名称为手机数码的所有商品
select * from product where cno=( select cid from category where cname ='手机数码');
多表查询练习数据
- 员工信息表
sql --员工信息表 CREATE TABLE emp( empno INT, ename VARCHAR(50), job VARCHAR(50), mgr INT, hiredate DATE, sal DECIMAL(7,2), comm DECIMAL(7,2), deptno INT ) ;INSERT INTO emp values(7369,'SMITH','CLERK',7902,'1980-12-17',800,NULL,20); INSERT INTO emp values(7499,'ALLEN','SALESMAN',7698,'1981-02-20',1600,300,30); INSERT INTO emp values(7521,'WARD','SALESMAN',7698,'1981-02-22',1250,500,30); INSERT INTO emp values(7566,'JONES','MANAGER',7839,'1981-04-02',2975,NULL,20); INSERT INTO emp values(7654,'MARTIN','SALESMAN',7698,'1981-09-28',1250,1400,30); INSERT INTO emp values(7698,'BLAKE','MANAGER',7839,'1981-05-01',2850,NULL,30); INSERT INTO emp values(7782,'CLARK','MANAGER',7839,'1981-06-09',2450,NULL,10); INSERT INTO emp values(7788,'SCOTT','ANALYST',7566,'1987-04-19',3000,NULL,20); INSERT INTO emp values(7839,'KING','PRESIDENT',NULL,'1981-11-17',5000,NULL,10); INSERT INTO emp values(7844,'TURNER','SALESMAN',7698,'1981-09-08',1500,0,30); INSERT INTO emp values(7876,'ADAMS','CLERK',7788,'1987-05-23',1100,NULL,20); INSERT INTO emp values(7900,'JAMES','CLERK',7698,'1981-12-03',950,NULL,30); INSERT INTO emp values(7902,'FORD','ANALYST',7566,'1981-12-03',3000,NULL,20); INSERT INTO emp values(7934,'MILLER','CLERK',7782,'1982-01-23',1300,NULL,10); INSERT INTO emp values(7981,'MILLER','CLERK',7788,'1992-01-23',2600,500,20); ```部门信息表```sql CREATE TABLE dept( deptno INT, dname varchar(14), loc varchar(13) );INSERT INTO dept values(10, 'ACCOUNTING', 'NEW YORK'); INSERT INTO dept values(20, 'RESEARCH', 'DALLAS'); INSERT INTO dept values(30, 'SALES', 'CHICAGO'); INSERT INTO dept values(40, 'OPERATIONS', 'BOSTON');
- 基本查询
sql --所有员工的信息 --薪资大于等于1000并且小于等于2000的员工信息 --从员工表中查询出所有的部门编号 --查询出名字以A开头的员工的信息 --查询出名字第二个字母是L的员工信息 --查询出没有奖金的员工信息 --所有员工的平均工资 --所有员工的工资总和 --所有员工的数量 --最高工资 --最少工资 --最高工资的员工信息 --最低工资的员工信息
- 分组查询
sql --每个部门的平均工资
- 子查询
```sql -- 单行子查询(> < >= <= = <>) -- 查询出高于10号部门的平均工资的员工信息
-- 多行子查询(in not in any all) >any >all -- 查询出比10号部门任何员工薪资高的员工信息
-- 多列子查询(实际使用较少) in -- 和10号部门同名同工作的员工信息 -- Select接子查询 -- 获取员工的名字和部门的名字 -- from后面接子查询 -- 查询emp表中经理信息 -- where 接子查询 -- 薪资高于10号部门平均工资的所有员工信息 -- having后面接子查询 -- 有哪些部门的平均工资高于30号部门的平均工资
-- 工资>JONES工资 -- 查询与SCOTT同一个部门的员工 -- 工资高于30号部门所有人的员工信息 -- 查询工作和工资与MARTIN完全相同的员工信息 -- 有两个以上直接下属的员工信息 -- 查询员工编号为7788的员工名称,员工工资,部门名称,部门地址 ```
- SQL查询的综合案例
-
查询出高于本部门平均工资的员工信息
-
列出达拉斯加工作的人中,比纽约平均工资高的人
- 查询7369员工编号,姓名,经理编号和经理姓名
- 查询出各个部门薪水最高的员工所有信息
面试题
```sql CREATE TABLE test( name CHAR(20), kecheng CHAR(20), fenshu CHAR(20) );
INSERT INTO test VALUES('张三','语文',81), ('张三','数学',75), ('李四','语文',76), ('李四','数学',90), ('王五','语文',81), ('王五','数学',82);
--请用一条Sql语句查处分数大于80的学生 ```